
Projects
This page includes my Ph.D. projects from 2019 to 2024.
Table of Contents
Stochastic modeling and Bayesian optimization
About Bayesian optimization
Determining regions of interest in discrete point data
To determine an optimal solution in the expensive unknown function, general Bayesian optimization methods sequentially sample the space by maximizing an acquisition function defined over the posterior of the Gaussian process (GP) model and according to past samples and evaluations. This requires the continuality of the search space so that the GP model can indicate the correlation among input samples. Nevertheless, if our observations are point events (e.g., following a Poisson process), GP cannot perform accurate modeling over those discrete samples.
Therefore, we choose a doubly stochastic point process, the Gaussian Cox process (GCP) with a non-negative smooth link function (connecting the Poisson process with an underlying GP) as the surrogate model for point event intensity to achieve our point data Bayesian optimization (PDBO). We formulate a Maximum a posteriori inference of the functional posterior of latent intensity and solve its mean and covariance via the Laplace approximation and kernel transformation in reproducing kernel Hilbert space. On top of that, we consider a wide range of special acquisition functions, such as detecting peak intensity, idle time, change point, and cumulative arrivals, through the underlying GCP model to efficiently discover regions of interest (ROIs) in a large discrete point dataset.
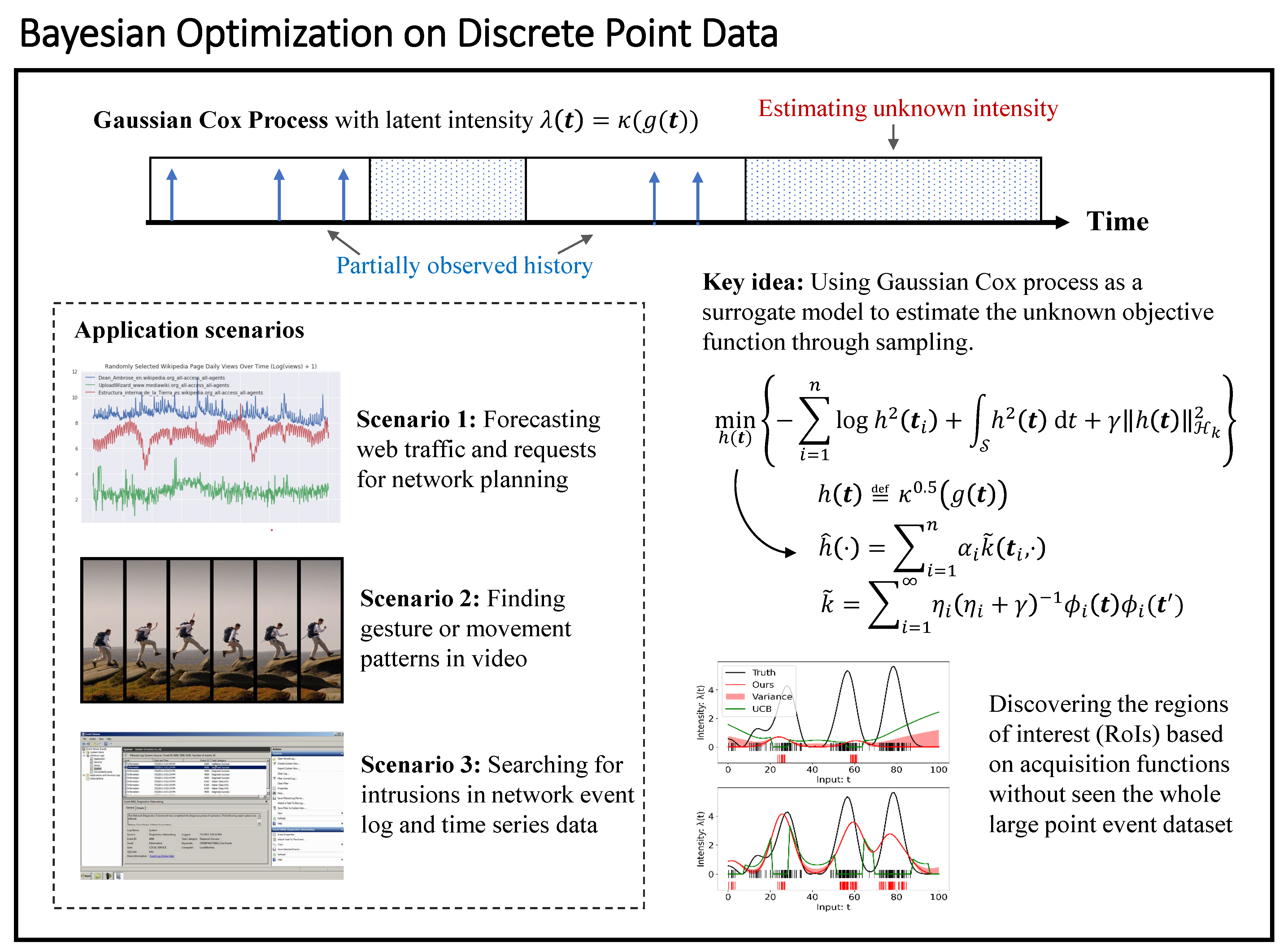
Fig. Bayesian optimization using Gaussian Cox process model on discrete point data.
Locating high crime rate regions in Washington, DC, USA
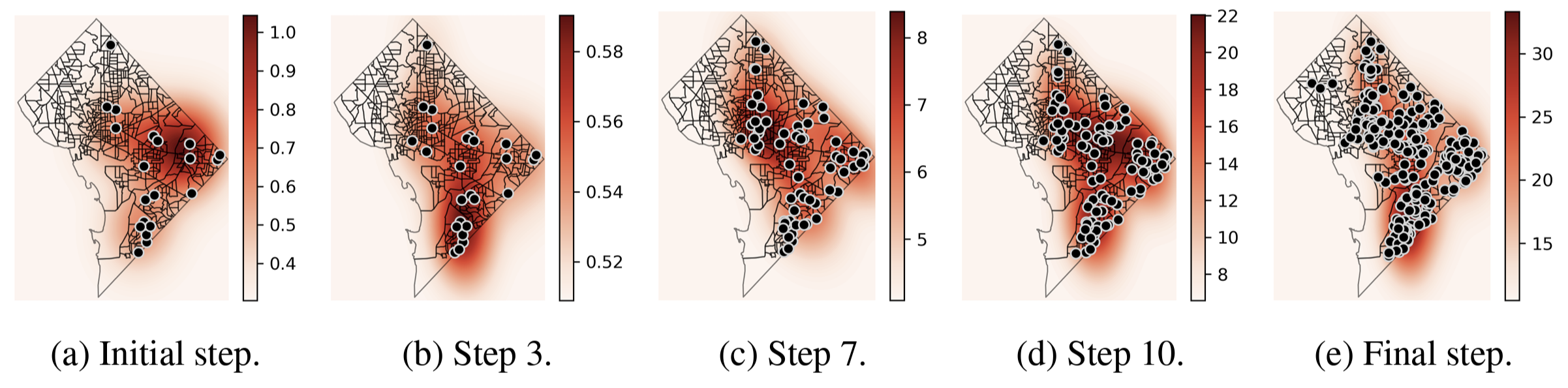
Fig. Key step visualization of BO on 2022 DC crime incidents data. Darker red reports regions with higher firearm violence crime rates.
Unveiling sub-optimal solutions of an unknown function
Giving up the optimal solution while turning to a sub-optimal one is painful. However, even if finding all or most global optima is desired in many real-world problems that can be seen as multimodal optimization, implementing the optimal solutions is sometimes infeasible due to various practical restrictions, such as resource limitations, physical constraints, etc.
We developed a multimodal Bayesian optimization (MBO) framework to locate a set of local/global solutions of a given unknown expensive function. We derive the joint distribution of the objective function and its first-order gradients (that are not considered in standard BO frameworks) and introduce new acquisition functions backed by this joint distribution to decide local optima sequentially during optimization.
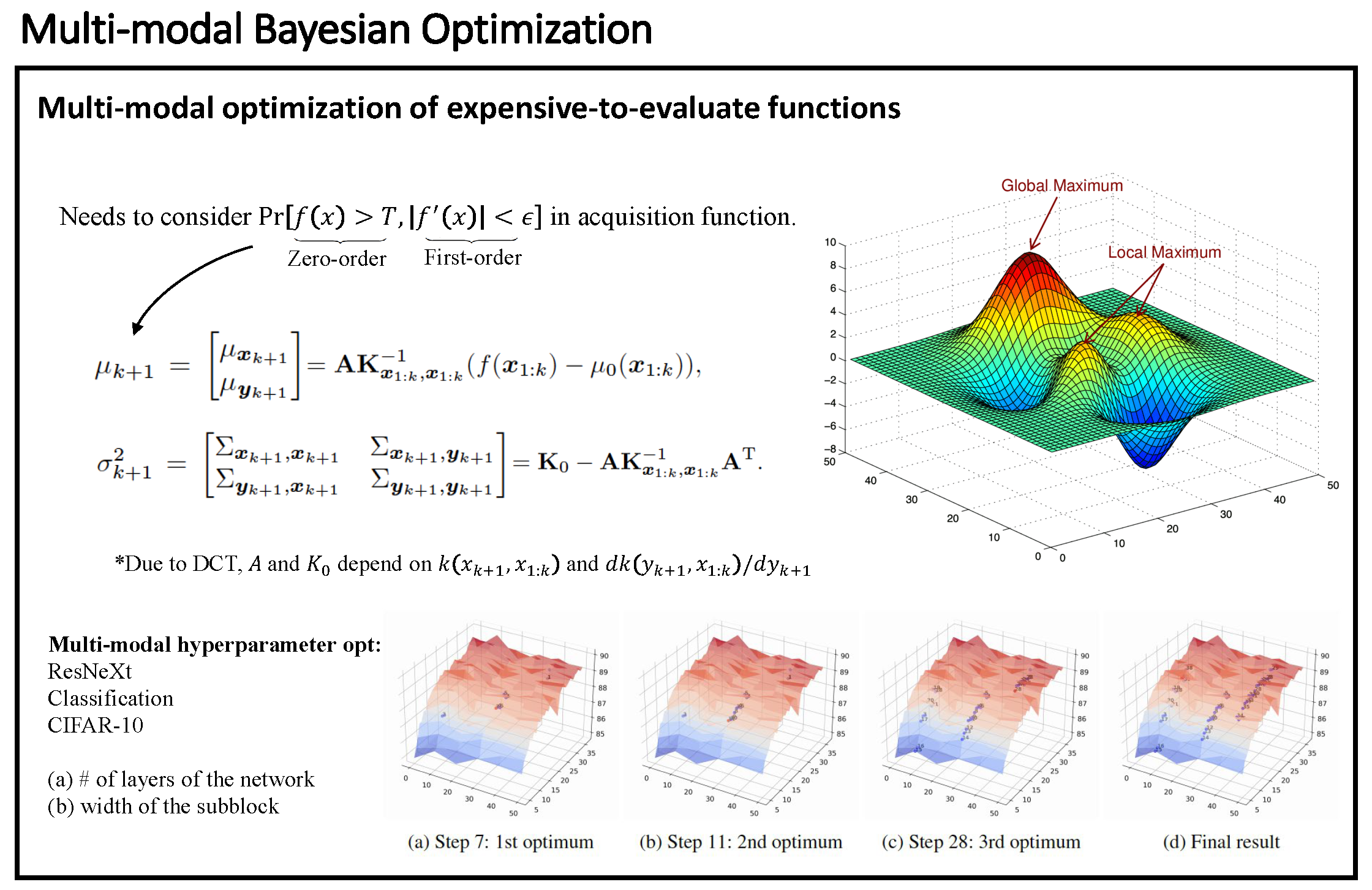
Fig. Multi-modal Bayesian optimization.
Medical image segmentation
Segmenting the precise brain tumor via attention to common information
The multimodal data allows the identification of correlated information shared by different modalities, i.e., common information, thus achieving better representations by the resulting neural networks. From the information theory perspective, the most informative structure between modalities represents the feature representation of one modality that carries the maximum amount of information toward another. To better measure the latent microstructure within the common information, we designed the partial common information mask (PCI-mask) to identify the latent partial common information shared by subsets of different modalities in finer granularity. The PCI-mask is optimized online in an unsupervised fashion during the learning.
Besides, we add a self-attention module that takes the PCI masks and concatenated feature representation of each modality as inputs to obtain the attention feature representation carrying precise partial common information. This module will discriminate different types and structures of partial common information by selectively assigning different attention weights. Thus, utilizing the PCI-mask and self-attention makes our segmentation algorithm more capable of avoiding treating different modalities as equal contributors during training or over-aggressively maximizing the total correlation (e.g., Hirschfeld-Gebelein-Renyi maximal correlation) of feature representations.
The proposed method optimizes the common information in feature representations of multimodal brain tumor data inputs, which allows precise segmentation with attention to microstructures. The framework is evaluated on the public brain tumor dataset: Multimodal Brain Tumor Segmentation Challenge, where we achieved the Dice scores (median) of 0.920, 0.897, 0.837 for the whole tumor, tumor core, and enhancing tumor, respectively.
System diagram
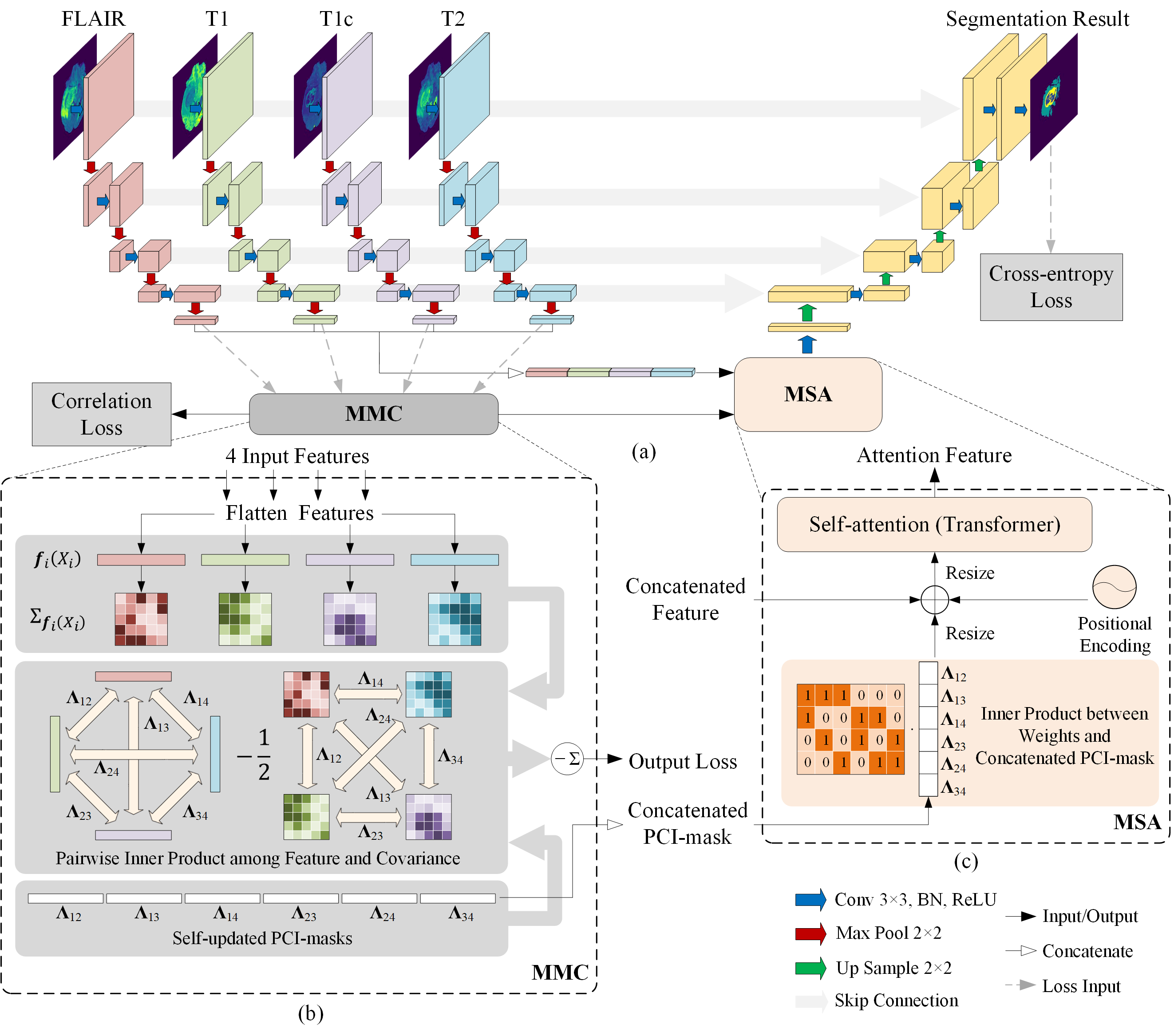
Fig. The system architecture (a), Masked Maximal Correlation (MMC) module (b), and Masked Self-Attention (MSA) module (c).
Segmention results
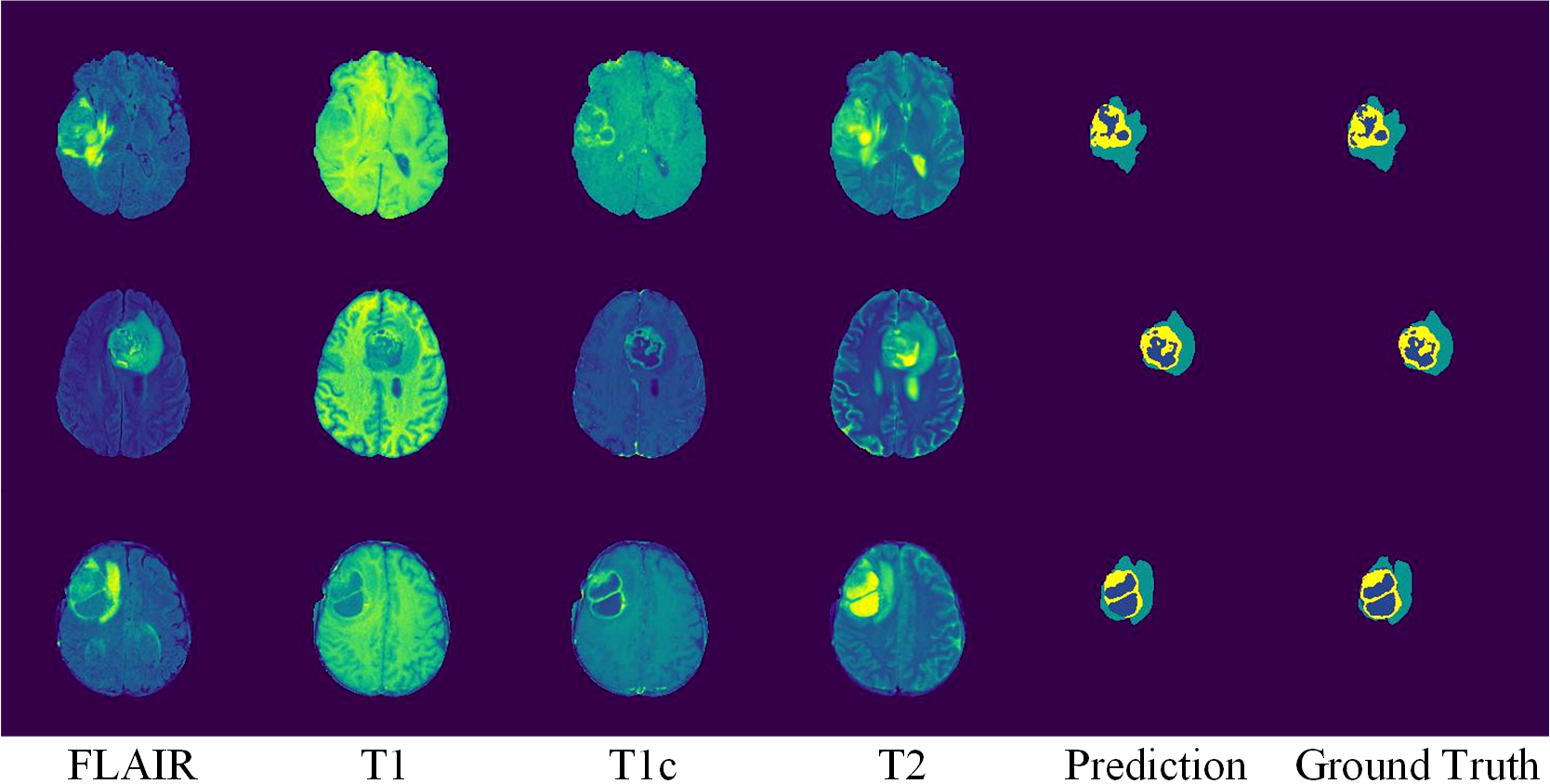
Fig. Visualization of segmentation results. From left to right, we show axial slices of MRI images in four modalities, predicted segmentation, and ground truth. Labels include ED (cyan), ET (yellow), and NCR/NET (blue) for prediction and ground truth.
Reinforcement learning
About reinforcement learning (RL)
Remixing monotonic projection with theoretic explanation
Value function factorization is the prevalent approach to dealing with multi-agent RL problems. Many of these algorithms ensure the coherence between joint and local action selections for decentralized decision-making by factorizing the optimal joint action-value function using a monotonic mixing function of agent utilities. Despite this, utilizing monotonic mixing functions also induces representational limitations. We aim to find the optimal projection of an unconstrained mixing function onto monotonic function classes. The results obtained via solving an optimization problem defined as expected return regret on QMIX (ReMIX) provide a theoretic explanation of the optimal projection to the intuitive weight assignment proposed in WQMIX.
Mean reward on Predator-Prey
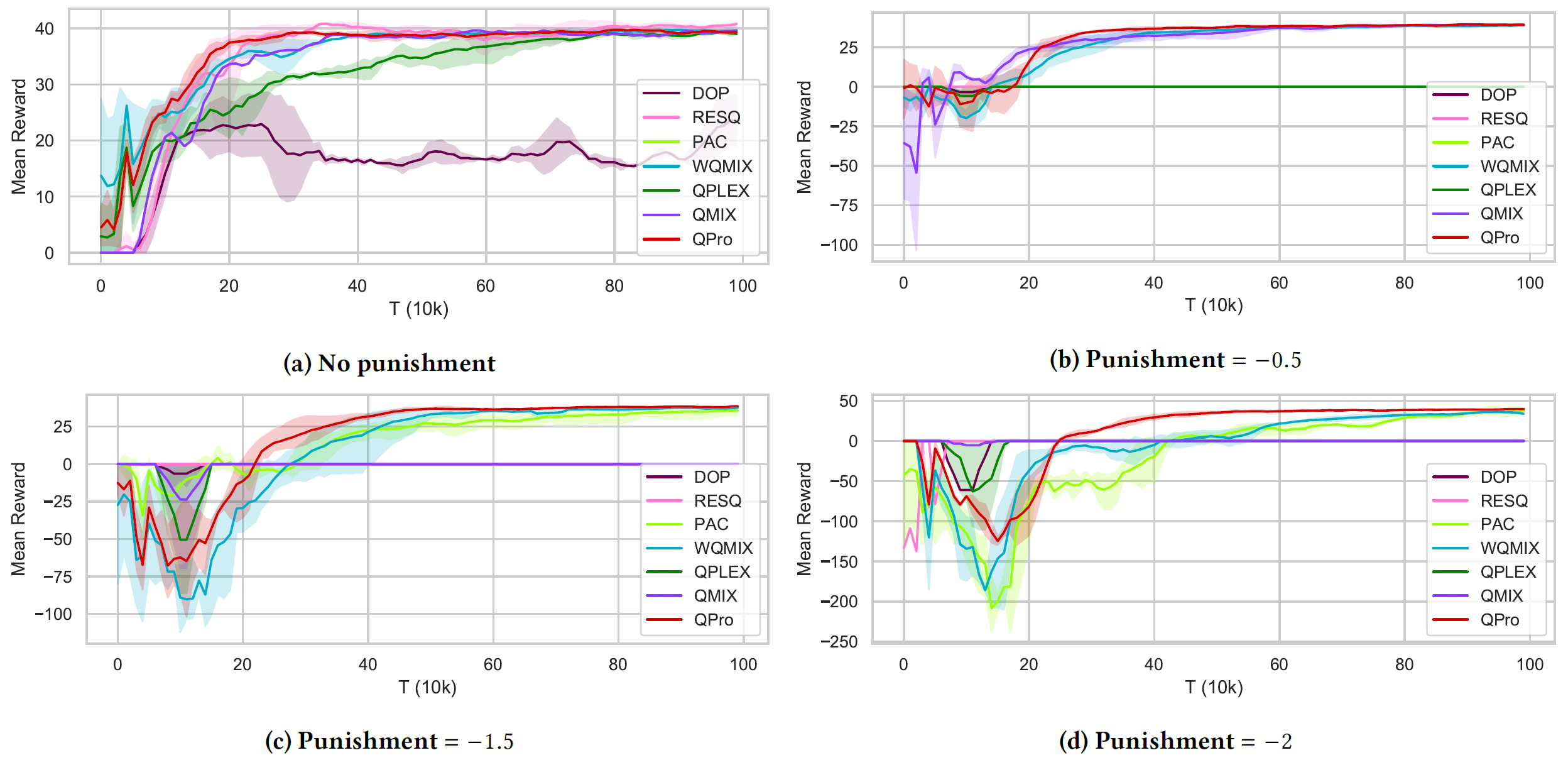
Fig. Average reward per episode on the Predator-Prey tasks of four punishment levels.
Prioritized sampling for multi-agent RL
We formulate a multi-agent collective prioritization optimization (MAC-PO) problem and solve it to acquire the optimal weight solution to emphasize the importance of the trajectories. Following the prioritized experience replay scheme, we extend the prioritized weight assignment to the multi-agent RL scenario, where the agents’ individual action-value functions contribute to determining the weights. Based on our findings, the joint action probability function $\boldsymbol{\pi}$ reaches its maximum if and only if (i) the value of each individual’s action probability $\pi^i$ is either 0 or 1, and (ii) at least one probability $\pi^i$ equals 0.
Specifically, we use several case studies to illustrate our findings. In case 1, even if the probability of selecting $\bar{Q}$ for both agents is large, we will not assign this action combination higher weight since its action probabilities $\pi^1,\pi^2$ cannot satisfy the mentioned criterion (i). In case 2, similarly, since $\bar{Q}$ and $\bar{Q}’$ equally share the importance, the action combinations with only one different agent’s action will be assigned with medium weights. In case 3, if one or more action values are extraordinarily large, indicating another joint policy candidate with latent high joint action probability, we should also heed such equivalent competitor and its local searches.
Special case studies
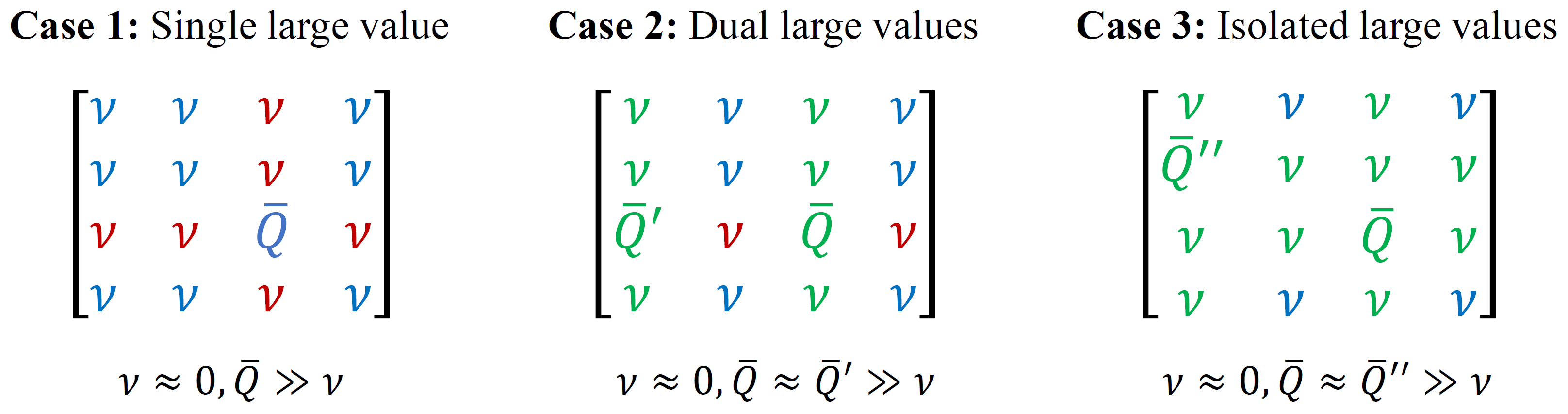
Fig. Illustration of action values for two-agent special cases, where each agent has an action space of size 4. The agent policy is defined in the Boltzmann manner. In the figure, the red, blue, and green action combinations will be assigned high, low, and medium weights, respectively.
Win rate on Starcraft Multi-Agent Challenge
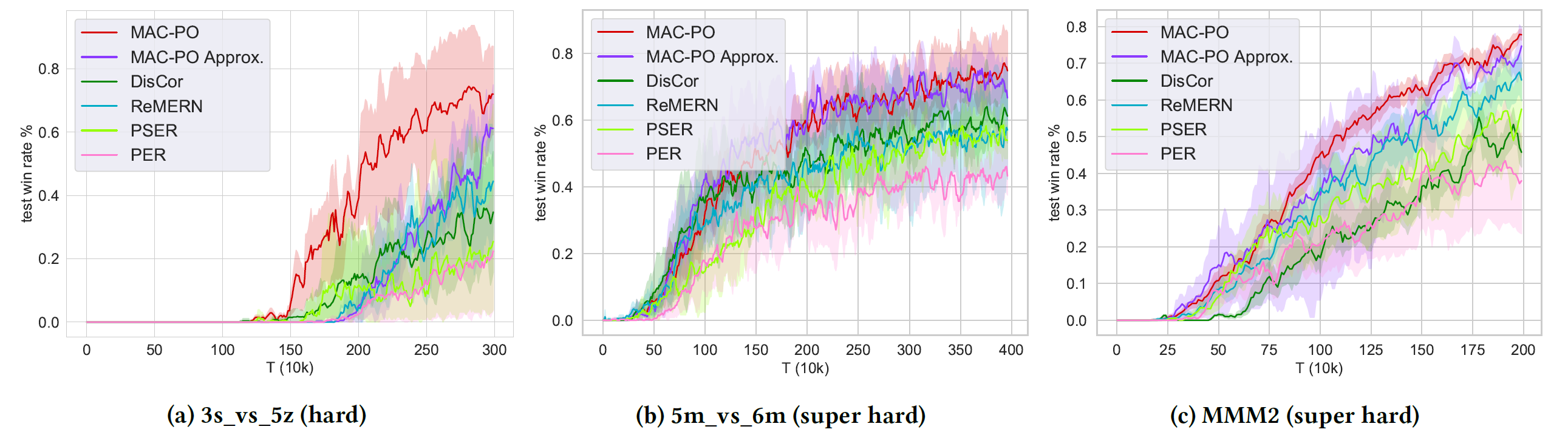
Fig. Comparison between MAC-PO and other adapted experience replay methods on three SMAC maps (from hard to super hard), where MAC-PO outperforms the runner-up by 10%, 6%, and 4% on each map, respectively.
Accelerating multi-agent RL
The sampling phase matters in off-policy RL, where a batch of transitions is uniformly sampled from the memory replay buffer in normal circumstances. We identified the bottleneck during this sampling stage, and to handle it, we can reuse a set of transitions we have already sampled from the replay buffer. We designed an acceleration framework in multi-agent off-policy RL. This data reuse strategy will accelerate the multi-agent experience replay (AccMER) guided by the priority weights.
Illustration of data reuse
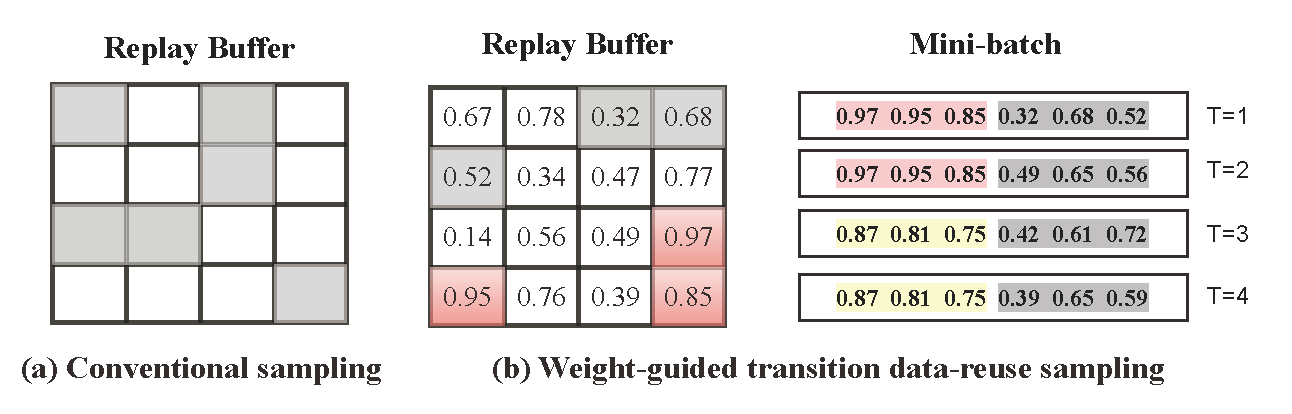
Fig. Illustration of (a) conventional sampling, where gray-filled boxes denote the uniformly sampled transitions from the replay buffer, and (b) data reuse sampling. In the figure, we sample 50% and reuse the rest of the transitions (reuse ratio = 0.5, batch size b = 6, replay buffer D is a 4×4 matrix), and the number of reuses (time-steps) n = 2. At step T = 1, as the data reuse ratio is 0.5, AccMER selects the first three transitions with the highest weights, and in the next phase, uniform sampling is performed on the remaining three transitions. At step T = 2, the same transition data will be reused, whereas a new set of transitions is sampled randomly. Since n = 2, the reuse-based transition data updates every two steps (e.g., T = 2 and T = 4).
Network security
With protocol dialects, a windtalker
What is the protocol dialect? Given a standard communication protocol, a dialect is defined as a variation created by mutating its packets and handshakes while keeping the communication functionalities unchanged. Like two code talkers on the client and server sides, they speak a specific dialect that is not understandable to outsiders. We design the moving target defense with generated protocol dialects (MPD) to mutate the dialect dynamically for each handshake in a network system. Besides, we incorporated the self-synchronization mechanism (inspired by the self-synchronizing stream cipher) to ensure the synchronization of both sides and minimize the lost when encountering a disaster. All generated protocol dialects are managed through the consistent hashing mapping. The system has been evaluated for multiple common network and Internet of Things (IoT) protocols, such as FTP, HTTP, MQTT, CAN bus, etc.
System diagram
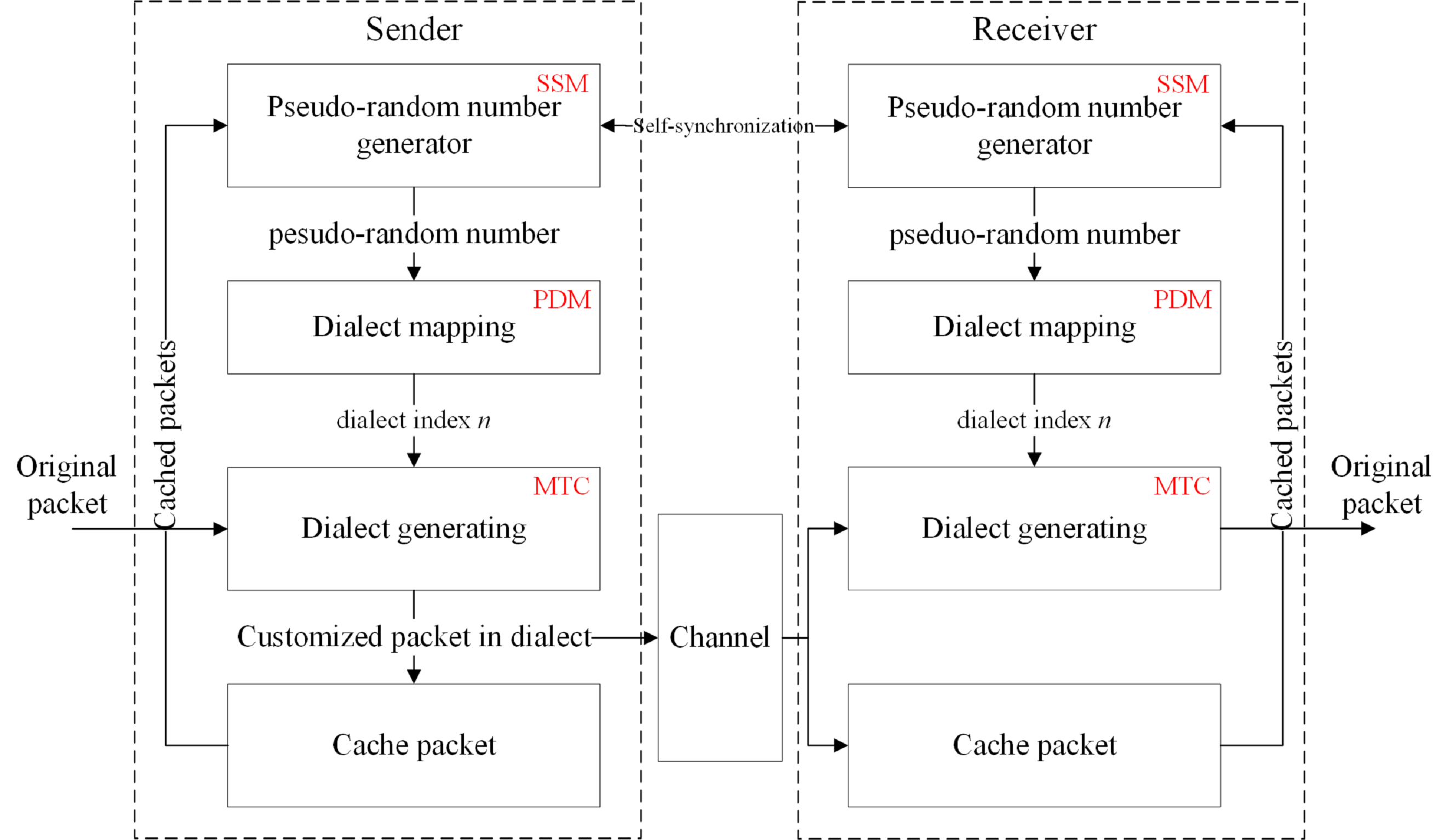
Fig. MPD system diagram, including Moving Target Customization (MTC), Self-Synchronization Mechanism (SSM), and Protocol Dialect Management (PDM) modules.
Self-synchronization
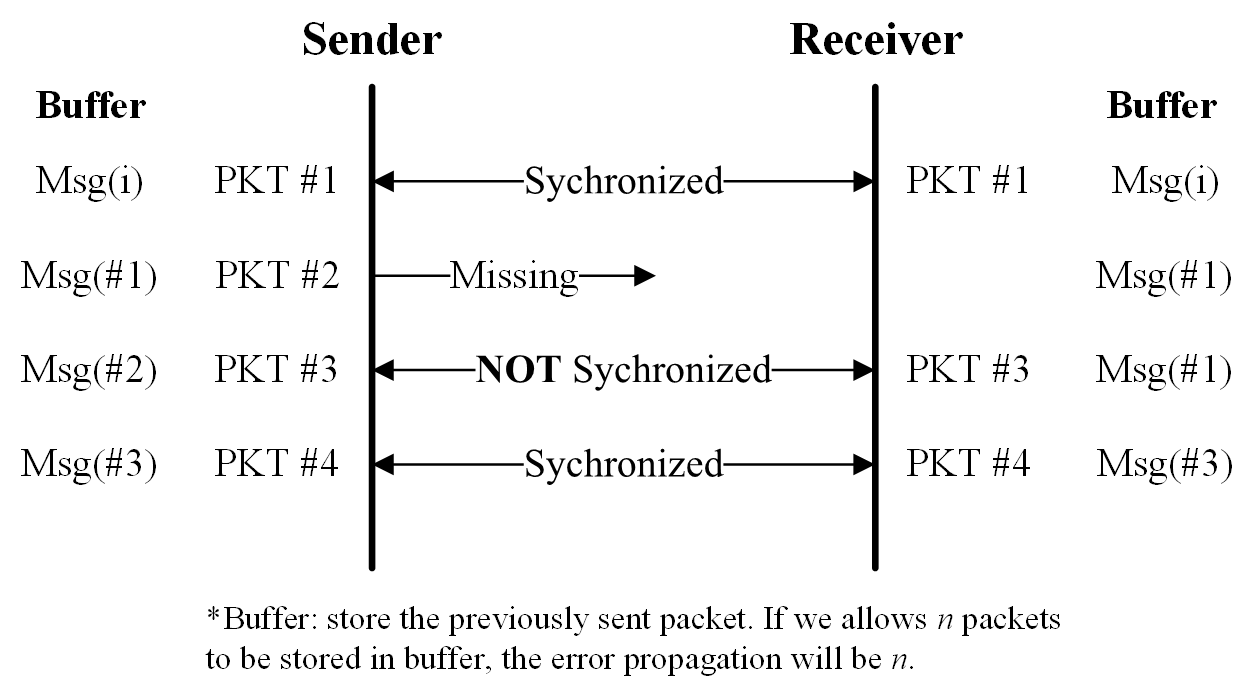
Fig. Self-synchronization mechanism. The system will re-establish the right dialect communication quickly after the disaster happens.